A short life cycle
The second feature of high-tech products is that they are developed and replaced at a high rate. Such a cycle of replacement is driven by the exponential performance achieved by researchers in the improvement (and sometimes also the replacement, as we will see next) of existing technologies.
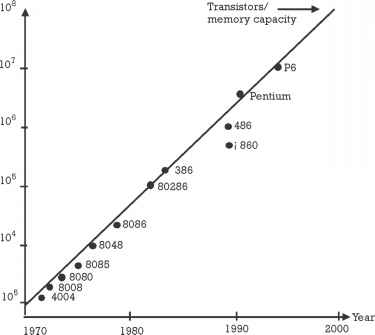
The archetypal and emblematic example involves microprocessors. Moore's Law—named after Gordon Moore, one of Intel's founders—clarifies the development of product performance: the number of transistors per memory circuit on integrated circuits doubles every 18 months (see Figure 1.4). This exponential growth and ever-shrinking transistor size result in increased performance and decreased cost. Engineers at Intel
Transistors /memory capacity 100 million
Transistors /memory capacity 100 million
• Microprocessor
Figure 1.4 Evolution rate of memory capacity of Intel microprocessors. (Source: Intel annual reports and press reports compiled by Eric Viardot.)
• Microprocessor
Figure 1.4 Evolution rate of memory capacity of Intel microprocessors. (Source: Intel annual reports and press reports compiled by Eric Viardot.)
managed to store twice as much binary data in a single-flash memory chip, while researchers at IBM discovered a way to replace aluminum conductors in microchips with copper, which is faster and cheaper. In addition, another researcher has managed to create a prototype with a data storage capacity that is 300 times more powerful than the average chip using a bacterium that lives in a salty environment, the bacteriorhodopsin. In a surprising twist, biotechnology is encountering information technology.
Moore's Law does not seem to apply exactly to telecommunication technology, since speeds are doubling on optical fibers every 12 months, and are now approaching 1 terabyte per second (see Figure 1.5).
Biotechnology is also experiencing the principle of exponential growth in performance within a shorter time frame. The case of the Human Genome Project is a prime example. The project began in the early 1990s in order to identify the genes responsible for hereditary diseases, as well as more common diseases, such as cancer and diabetes, and to design new therapies and new drugs. To do so required locating the 40,000 genes and 3 billion nucleotide bases (or combinations of genes) that form the human genetic structure. At the outset, that looked like a very complex task, because it required screening billions of bits of information, which could have fill one thousand 1,000-page phone books. The project was initially forecast to take until 2005, but the first map was actually completed in June 2000, 5 years ahead of schedule, thanks to the massive use of technology.
")
- Figure 1.5 Increase in bit rate-distance product during the 1850-2000. The emergence of a new technology is marked by a filled circle. (After: [21].)
In 1983 it took six people working a total of 3,300 man days to identify 4,000 bits of information, an average of 1.2 combinations a day. By 1998, it took one person 8 hours to identify 50,000 nucleotides, an average of more than 17 per second. Today it takes one person 2 minutes to identify 50,000 nucleotides, an average of more than 417 per second. And by 2005, it is estimated that it will take one person 10 seconds to identify 50,000 nucleotides an average of more than 5,000 per second (and the entire human genome in less than 10 seconds).
Scientists are now working on the Human Proteome Project. The goals and endpoint of the project remain undefined, but include the structural and functional determination of at least one protein in each protein family. Once a single protein from each fold family has been identified and structured, homology modelling can be used to predict the structure and potential functions of other proteins in the same family [22]. Revealing the mysteries of proteins will allow scientists to create customized drugs, which can meet the individual needs of each patient. One example of such an application is a current drug for HIV patients, which is based on the three-dimensional structure of the HIV-1 protease protein [23]. But this project is on a scale exponentially larger than the Genome Project, because the number of proteins is estimated in the hundreds of thousands, with trillions of combinations.
Continue reading here: The physical and virtual value chain model
Was this article helpful?